This is a guest post, written by Philip Dürholt, a student in the “Digital Humanities” program (BA and MA) at the Department for Literary Computing, University of Würzburg. As always, comments are welcome!
I’m a student at the University of Würzburg. My subjects are Philosophy and Digital Humanities. Last winter semester I had an interesting mix of courses: Quantitative Analysis of Dramatic Works and Linguistic Textual Corpora. As it was time to write the assignment at the end of the semester, it came to my mind to blend what I had learned. It seemed to me, that what I learned in the linguistic textual corpora class could benefit the quantitative analysis of plays, so why not try it?
In quantitative analysis of plays we used an XML/TEI tagged corpus of 57 German plays that were written between the 18th and 19th centuries. We learned to use the R-Package stylo for analyses that could help indicate the author of an array of plays. In linguistic corpora we learned about POS-Tagging and I chose to prepare a presentation about the RFTagger. This tagger comes with a package of parameter files for different languages, one of them is German. Under best conditions it has a tagging accuracy of 98,7% (see “Better tags give better trees – or do they?“). I was baffled by the fact that it seems to be possible to let a machine automatically add fine-grained lexical information to plain text. Having experienced this, an idea was born: What if I took a text, added POS-Tags, and prepared a whole variety of layers, which represent the text, and then put them through stylometric analysis?
It seemed to me that this procedure could let me generate graphs that show different outcomes, maybe harvesting signals from the text that I had not paid attention to yet. I was prepared to find a lot of nonsense, but then again hoping for interesting and unseen analytic gems. Perhaps some of the prepared corpus versions would tell me something about the difference in the way Schiller and Goethe composed their sentences.
The MFW (Most Frequent Words) analysis of the stylo package produces graphs that show the statistical similarity between texts, which indicates that those texts with high similarity could have been written by the same author. This sounds great, but it is still not perfectly accurate. So what if the addition of POS-Tagging brought up better results? It was time to get into something new. I couldn’t find much literature to that mix of disciplines. So I started to run a variety of tests.
The raw material
The corpus I used was the one from the course about quantitative analysis of plays. It consists of 57 German plays that were written between 1747 and 1846 and can be therefore considered as part of the Age of Enlightenment and the Sturm und Drang period. The plays are a selection of the works by Goethe, Schiller, Arnim, Lessing, Kleist and other German canonical play writers (found in the TextGrid Repository), the dataset used is available via Zenodo.[]. The data consists of xml files, since the plays had been enriched with meta-information through TEI encoding. So there was some work to do before the POS-Tagging could take place. The RF-Tagger would read the TEI Tags as if they were written language, which I couldn’t use. So I first ripped all TEI Tags from the corpus. Easy with regular expressions (I found useful information on that at stackoverflow).[]
After that I had to tokenize all the texts. The RF-Tagger would do that automatically if I had used a Linux machine to perform my experiments, but I only had access to a Laptop running Windows 8. So I ran every text through the RF-Tagger Tokenizer. At last there was the Tagging itself. With the RF-Tagger you call the annotate function and a parameter file containing the information for a specific language. Since I was new to command line operating and hadn’t used the time to research before starting to work (probably because of my impatient nature) I called every one of those functions for every one of the 57 plays one after another. In total I typed 171 commands of which some took a few minutes to process and even some more commands to rename the output files and move them to other folders. This made me spend one night awake.
The next afternoon, after sleeping the first half of the day over, I decided to look for more adequate ways of calling functions automatically for a variety of files. Remember I was working on a windows machine, but for the command line work I used Cygwin (a Linux emulator for Windows). This way I was able to work with linux syntax and many useful linux packages. I found that you can write for-loops directly to the command line. That changed everything and made me feel stupid about the time I spent typing all commands by hand.
Now I had the whole corpus tagged with POS information, but that wasn’t the data I wanted to have quite yet. For the stylo analysis, I thought of some versions of the corpus: The first one is the POS-only corpus. For this, I run all texts through the RFTagger and then rip all original text off the files, to use the POS-Tags only for analysis. For a second version, I filter the POS-Tagged corpus for all adjectives and remove everything else. The analysis runs on texts that consist of adjectives only. I use the same procedure to generate a nouns-only and a verbs-only version of the corpus.
The testing
Next I took all versions and ran them through the stylo analysis, tweaking the parameters of every test on every corpus version. Here are some of the results:
The first graph shows a cluster analysis of the corpus in its original state – XML/TEI tagged texts. I used the 50 MFW and a culling of 90% (only words that are found in 90% of all texts are used), excluding pronouns.

Figure 1: Cluster Analysis based on full XML text
The Cluster Analysis provides information about the similarity in style with which a text was written. The expected outcome is therefore, that the plays of one author get clustered together and are positioned further away from those of other authors. In this graph we can see that the analysis shows useful information about the plays of most of the authors. Especially for Lenz, Lessing, Schiller and Wieland. For most of the other authors, it shows viable results. Only Brentano and particularly Kleist are pretty much scattered all over the place.
For the next test, I tried to find a way to improve the outcome for those authors, who were represented badly in the first test. Using the 269 MFWs and a culling of 0% on a corpus that consists of the POS-Tags only, I found the following results:
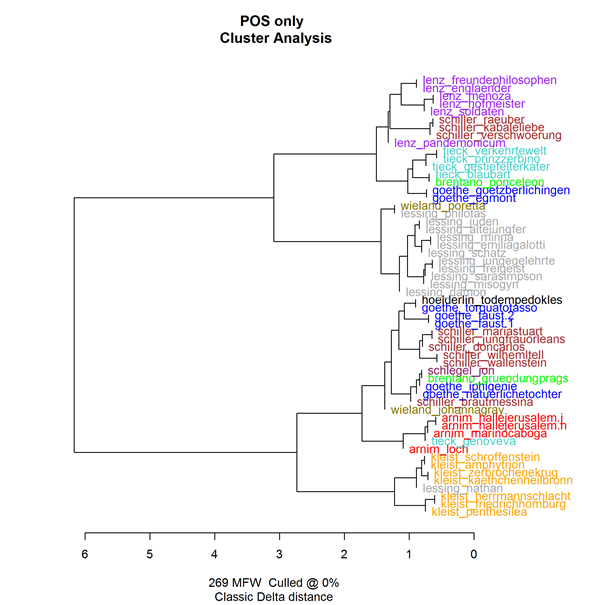
Figure 2: Cluster Analysis based on POS-tags only
Here we can see a graph that could be considered a failure, except for the fact that it shows pretty good results for the plays of Kleist. I should mention that Lessing clustered in a remarkably robust manner, no matter what parameters or corpus version were used.
I chose to show the following third Cluster Analysis to present the results using a corpus of adjectives only. Parameters were 700 MFW and a culling of 0%.

Figure 3: Cluster Analysis based on adjectives only
This analysis at least shows some acceptable results for Tieck and Lenz (despite outliers) and an excellent result for Kleist, not to mention the Lessing-Fortress. Besides that, the tremendous distance that separates one half of the Schiller plays from the others is striking.
As you can see, there are some analyses that fit into what we expected, and some don’t seem to show the information we want. But overall we can observe some phenomena that could catch one’s attention. See how the cluster analysis behaves in respect to the results for Kleist and Schiller. I kept tweaking with the parameters and used several different versions of the corpus and most analyses had ‘good’ (or useful) results either for Kleist or Schiller but not for both at the same time – yet there were enough ways to get useless results for both of them. We can observe this comparing the first Cluster Analysis with the other graphs. The first one shows excellent results for Schiller but – apparently – without catching any style related signal from Kleist plays. The other graphs show the exact opposite results: excellent Kleist but disastrous Schiller. I called it the Schiller-Kleist uncertainty principle.
After all the testing and observing I wanted to rate the efficiency of the different analyses and found out, that the ‘normal’ analysis with the original TEI tagged corpus, choosing XML-input in stylo, performed best. Not only for the whole of the data but also for the individual authors in comparison to any other version of the corpus. But then again, this wouldn’t be everything that can be learned from this. The following table shows a simple rating matrix, comparing the success rate of the Cluster Analysis:

Figure 4: Cluster Analysis Quality for different runs
For each method of analysis, I counted the number of plays of one author in the biggest group/cluster and divided it by the total amount of plays from that author. So a 1.0 means, that all texts of an author were grouped together and, say, 0.5 means that the plays were divided into two equally sized groups. The graph shows that the stylo analysis of the XML corpus shows best results in total for most of the authors. Arnim, Lenz, Lessing, Schiller and Wieland were all clustered perfectly. This is the highest amount of correctly clustered texts in all analyses. The Schiller-Kleist phenomenon can be seen comparing the XML run 1 and XML run 2. In the first try we see 0.57 for Kleist and 1.00 for Schiller, and in the second try we see 1.00 for Kleist and 0.56 for Schiller. The different runs are different parameter settings in stylo.[]
Final thoughts
The fact that different corpus versions showed better results for certain authors caught my attention. In retrospection I had just chosen some arbitrary ways to transform the corpus and surely did not come up with the most sophisticated ideas to implement POS-Tagging in authorship attribution. So what if I had more experience, more knowledge of literature and an awesome strategy to find the best corpus version plus stylo parameters to have the best possible results in authorship attribution for a certain author?
I could craft authorship profiles, which contain all stylo parameters and the information of the corpus preparation that allow the analysis to perform best for the author in question. Even more, I could go and compare the profiles with one another and produce questions about what makes those certain parameters nail down the specific author in particular. And then again we could start thinking about meta-heuristics and profile analysis. So what is needed to expand the possibilities of authorship attribution? Maybe, it’s just giving it a try.
Notes
![[cxml]](/fct/images/cxml_doc.png)
![[csv]](/fct/images/csv_doc.png)
![[text]](/fct/images/ntriples_doc.png)
![[turtle]](/fct/images/n3turtle_doc.png)
![[ld+json]](/fct/images/jsonld_doc.png)
![[rdf+json]](/fct/images/json_doc.png)
![[rdf+xml]](/fct/images/xml_doc.png)
![[atom+xml]](/fct/images/atom_doc.png)
![[html]](/fct/images/html_doc.png)


![[RDF Data]](/fct/images/sw-rdf-blue.png)